Notes About Heap Overflow Under Linux
假期搞了次堆溢出,但是做的不是很多。再搞一次,强化下印象,顺便理解理解细节。没啥说明的话,都是在x64下做的。
Enterance
malloc是ptmalloc2内存分配器里的一个功能。而真正负责从虚拟地址里划分空间的,则是mmap以及brk等系统调用。malloc和free等,只是在mmap拿到的内存空间里进行二次分配的。这样涉及的原因是,由于mmap需要考虑到对齐等问题,不加管理的话可能造成资源和时间上的浪费。ptmalloc2为每个线程分别维护一套表,用来管理内存,可以减少不同线程之间的冲突。以下讨论的例子中,我们假设只要一个线程。
在程序启动时是不会创建堆的,如图:

第一次调用malloc后,会创建一个堆:

我们分配了一块4k的内存,但这个堆的大小是136KiB。预先分配空间,一定程度上可以降低分配时间。
接下来,我们分派了16个4kb的内存。使用gdb观察一下内存块的结构:

可以看到,分配的结构是这样的:

现在释放一个块看看:

可以看到,被释放的内存块结构变成了:

这里,我们将这两个指针称为fd和bk。注意到fd和bk指到了一个位于栈上的空间。gef的heap chunk指令,可以帮助我们查看关于这个内存块的信息:
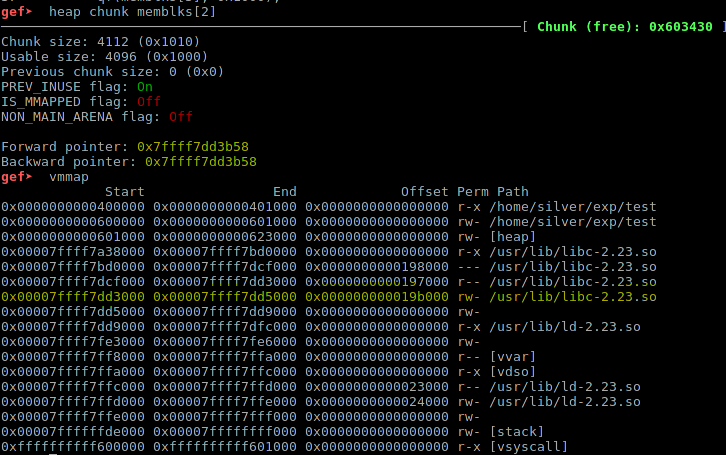
为了搞明白这些信息,我们需要关注一下ptmalloc的工作细节。
Faster! Faster!1
libc是一个历史气息浓重的库(充满了历史包袱,对),所以先来回顾一下其历史,有助于了解malloc及其工作机制。当然,希望你在阅读本段之前,已经了解了操作系统对内存的管理机制,也就是brk和mmap等系统调用。如果你还不太了解,推荐你读下这篇文章。
作者写作本文时,以glibc-2.9为基准。
历史包袱
目前一些比较常用的内存分配器有:
- dlmalloc - 通用内存分配器
- ptmalloc - 基本也就是glibc
- jemalloc - 在Firefox和FreeBSD中使用的分配器
- tcmalloc - Google使用的分配器
- libumem - Solaris使用的分配器
- ...
glibc起初采用dlmalloc作为其默认分配器。随着时间的推移,dlmalloc的问题也逐渐凸显出来。其中一个问题就是,由于没有考虑到多线程下的性能问题,dlmalloc存在锁冲突。在dlmalloc中,当两个线程同时调用malloc的时候,只有一个线程可以进入临界区2,这是因为所有活动的线程共用了同一个结构实例来管理内存。因此,在多线程程序中,dlmalloc造成了一定的性能损耗。
之后,glibc采用了ptmalloc作为自己的内存分配器。在ptmalloc2中,每个线程拥有自己“独立”的堆结构3,那么两个线程同时请求分配内存时,就可以无需阻塞,直接分得内存4。接下来,我们以Understanding glibc malloc一文中的示例代码为例,介绍一下ptmalloc是如何处理程序对内存的请求的。
注意:示例代码为32位
dlmalloc中对线程内存的管理
程序从操作系统获得内存之后,内存分配器会负责将其分配给各个线程,各线程请求内存时,分配器会检查可用的内存,并作出回应。这里先来说一说各个线程是如何获得内存的。
在示例代码的入口点停住,可以看到在malloc之前:
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
b7e05000-b7e07000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$可以看到,Loader已经把ELF映像中的三个segment映射到了内存里。由于我们还没有调用malloc,那么也就没有给我们分配一块堆。
调用了一次malloc之后,可以看到:
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
>>>>0804b000-0806c000 rw-p 00000000 00:00 0 [heap]<<<<
b7e05000-b7e07000 rw-p 00000000 00:00 0 这里可以看到,调用malloc之后,在0x804b000处分配了一个大小为0x21000的堆块。查看源代码可知,这时候的调用流程为:
malloc -> ...
-> __int_malloc(malloc/malloc.c:4128) # Entry
-> ...
-> __int_malloc(malloc/malloc.c:4454) # First call, thus no bins available
-> __int_malloc(malloc/malloc.c:4549) # A chain of if, and make sure no more available space
-> __int_malloc(malloc/malloc.c:4580) # So we need a new HEAP
-> sYSMALLOc(malloc/malloc.c:2906) # Judge which way is suitable
-> ...
-> sYSMALLOc(malloc/malloc.c:3044) # First malloc, and must be main_arena
-> sYSMALLOC(malloc/malloc.c:3097)
-> sYSMALLOC(malloc/malloc.c:3121) # Make extra space for manage heap
-> sYSMALLOC(malloc/malloc.c:3130) # Call malloc
-> MORECORE -> __morecore -> __default_more_core
-> __sbrk -> sbrk这里我们可以看到,主线程调用malloc获取到的内存,全部是由brk分配的。与mmap不同,brk不能在任意位置分配内存,也不会清零内存或修改权限。brk只是简单地向os申请更多的页,而且这些页都是在程序的bss段之后的(如果开启了ASLR,会加一个随机偏移量)。
此外,我们的malloc只申请了不到1k的内存,但申请后新开的堆大小为132KB。我们把这段连续的内存叫**arena** 5,而由于这段内存是由主线程建立的,因此称其为main arena。在主线程里,之后所有的内存分配都会从这块main arena里获取空间。当其空间耗尽时,malloc会再次调用sbrk,获取更多的内存,并修改相关的管理结构。而当我们用free释放掉这块内存时,会发现这块内存并没有被立刻返回给OS。这是因为无论在主线程还是在其他线程中,free到的内存都会由分配器进行决策,在合适的时机返回给内存,以便重复利用。我们后面会详细解释这一细节。
刚才我们介绍了主线程的内存是如何从OS获得的,而其他线程获得内存的方式则稍有不同。继续执行刚才的示例代码,可以看到在新的线程申请内存后,内存布局是这样的:
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
>>>b7500000-b7521000 rw-p 00000000 00:00 0 <<<
>>>b7521000-b7600000 ---p 00000000 00:00 0 <<<
b7604000-b7605000 ---p 00000000 00:00 0如果你顺着调用流程走下去的话,会发现这里的执行路径和之前完全不一样了:
malloc -> ...
-> __int_malloc(malloc/malloc.c:4128) # Entry
-> ...
-> __int_malloc(malloc/malloc.c:4580) # We need a new HEAP
-> sYSMALLOc(malloc/malloc.c:2906) # Judge which way is suitable
-> ...
-> sYSMALLOc(malloc/malloc.c:3044) # not new heap <<<!!!!!
-> sYSMALLOC(malloc/malloc.c:3053) # but also unable to expand heap
-> sYSMALLOC(malloc/malloc.c:3063) # So make a new heap by:
-> new_heap(malloc/arena.c:3130) # Entry. Some adj and check
-> new_heap(malloc/arena.c:673) # Get new memory
-> MMAP -> ... 不同于主线程,这里的内存是mmap申请得到的。另外,虽然我们仍然只请求了1KB的内存,但malloc为我们拿到了1MB的内存,其中只有前132KB被设定为rw权限,后面的内存会在需要时再次进行处理。我们把这前132KB称为thread arena。而同样,在free之后,这块内存也并没有立刻返回给OS。
此外,这里要注意的是,无论在哪个线程中,如果申请的内存大于128KB,malloc都会使用mmap进行分配,而永远不会使用sbrk。
在得到的第一块堆用尽之后,再次申请内存时,malloc会从操作系统为该arena再次申请一块内存(用mmap)6,因此,ptmalloc使用heap_info(malloc/arena.c:69)这一结构体来管理堆。此外,为了管理heap的内部空间,malloc使用了malloc_state(malloc/malloc.c:2317)这个结构体。这些结构体全部位于由OS新分配的内存空间中,也就是说,拿到了他们所在的地址,就拿到了对应堆块的地址。7
对堆中内存的管理
为了管理heap的内部空间,内存分配器引入了chunk的概念。ptmalloc把堆中的Chunk分为了四种:
- Allocated chunk
- Free chunk
- Top chunk (
mchunkptr top;(malloc/malloc.c:2333)) - Last Remainder chunk (
mchunkptr last_remainder;(malloc/malloc.c:2336))
在malloc_chunk(malloc/malloc.c:1773)中,给出了前两种Chunk的头部。下面我们分别讨论这几种Chunk。
Allocated Chunk
malloc_chunk实际上是一个“隐式空闲链表”,其设计目的在于可以用其头部信息定位到下一个块。
一个非空块指针p=malloc(SIZE),只有malloc_chunk.size一个成员的值对malloc是一定有意义的,且其地址为p-len(int),也就是说malloc_chunk类似于一个楔子,嵌入到内存块的头部8。这样,获取下一个chunk的地址时,可以用*(p-len(int))-2*len(int)+p来获得。而malloc_chunk.prev_size的情况比较特殊,需要视上一块的情况而定。如果上一块是空的,那么这里保存的就是上一块的大小,否则是一些无意义的用户数据,这一点要结合下一段来看。此时,其他的成员如malloc_chunk.fd等均未被使用,而用作数据空间。
此外,由于分配得到的内存地址和大小总是对齐的,因此可以利用malloc_chunk.size的低几个字节来保存一些标志位。其最低位PREV_INUSE代表了当前块内存空间的前一块是否被使用,而第二位IS_MMAPPED则代表了该块的获取方法。置1则代表该位是通过mmap获取的。
下图是一张比较直观的图,来自sploitfun。

Free Chunk
在我们用free(p)释放了刚才的内存之后,留下了一些管理信息。要理解他们的含义,首先给一个结论:
malloc总保证空闲块内是尽可能连续的
也就是说,一个空块之后一定是一个有数据的块或是堆尾。
由于p目前是个空块,那么有一些数据结构就有意义了。
首先来看第一个成员malloc_chunk.prev_size,由于空闲块之间总是不连续的,因此空闲块之前一定是一个在用的块,此时,malloc_chunk.prev_size里存放的是上一个块的最后几个字节。malloc_chunk.size的作用不再赘述。
之后是malloc_chunk.fd和malloc_chunk.bk。他们指向的是同一个bin(筐)里的下一块(而不是物理空间里的下一块)。筐是一种用来管理当前堆里空闲空间的数据结构,在稍后的一节里会详细介绍的。筐的结构也是我们能成功执行堆溢出攻击的重要因素之一。
下图是一张比较直观的图,同样来自sploitfun。

Top Chunk
我们都知道,堆地址是从低到高生长的,而在每个arena最顶部的Chunk就叫做top chunk。top chunk不属于任何筐,因为当筐里没有任何空块的时候,就从top chunk里取一部分内存空间,这时候top chunk被分为了两部分:一部分是user chunk,也就是给用户用的那部分,另一部分则是remainder chunk,也就是剩下的那部分。而如果top chunk比用户请求的空间还大,那么malloc就会视情况(主线程or其他线程)调用mmap或者sbrk来增大其堆空间。
Last Remainder Chunk
刚才我们提到了remainder chunk,它是top chunk被分配之后剩下的部分,而last remainder chunk指的就是top chunk最后一次被分割后剩下的部分。这里跟我们要做的没什么太大关系,就先不详细说明了。有兴趣的可以阅读malloc/malloc.c:4511及相关的代码。
Bin(筐)中如何管理空闲内存
ptmalloc不关心用户如何使用已经分配好的内存——讲道理,也没法关心——,而会主动管理空闲内存。受管理的空闲内存被置于一个名为”筐“的结构中,每个arena拥有自己的bin结构,其位置在malloc_state结构体中。根据设计需求,Bin也被分为四种:
- Fast bin (
mfastbinptr fastbins[NFASTBINS];(malloc/malloc.c:2330)) - Unsorted bin
- Small bin
- Large bin
其中,后三种被打包存放于mchunkptr bins[NBINS * 2 - 2];(malloc/malloc.c:2339)中。目前的malloc实现中共有126个bin,第一个为Unsorted bin,第2至63个为Small Bin,剩下的64~126号为Large Bin。下面我们分别了解下这几种结构。9
Fast bin
Fast bin中容纳的是Fast chunk,顾名思义,其分配和释放的速度都很快,因此其数据结构也比较固定。目前,Fast bin的项目数量被固定为10,每项都指向一个单链表,链表中包含了同一大小的内存块。在free时,如果程序判定内存块属于fast chunk,那么这些内存块的in_use位不会被修改,这样这些块就不会和其他的空块合并,从而影响fastbin的布局。在malloc初始化的过程中,规定了Fast Chunk的最大大小为80字节(malloc_init_state(malloc/malloc.c:2427)),并保证fast bin中每种chunk的大小相差8字节。
fast bin中容纳的是大小为16~64字节的空块10,这些空块都是由之前malloc之后free得到的,因此在程序第一次调用malloc的时候,无论如何都没办法从fast bin中获得内存。之后,如果fast bin非空,那么在申请小内存时,malloc会优先从fast bin中获得内存(malloc/malloc.c:4162),方法也比较简单,将对应链表的第一项项拆出来并返回就可以了(malloc/malloc.c:4174~4180)。
而在free的时候,也会首先检查是否可以放入fast bin中(malloc/malloc.c:4636),如果可以的话,在进行安全检查后,将其加入链表中(malloc/malloc.c:4668,4669)。这里借用sploitfun的图片,来说明fast bin的布局。

Small bin
所有小于512bytes的块被称为small chunk,被存放在small bin中。small bin中共有62项,每项大小相差8bytes,而且各项之间是可以被合并的,这样有助于减小内存碎片。small bin中,每项都是一个双链表,链表中每个空块的大小是一样的。
当程序申请一块大小适当的内存时,如果small bin非空11,那么malloc会试图从合适的small bin中(malloc/malloc.c:4193)取出队末的一块内存(malloc/malloc.c:4195)作为被返回的块,并将其从链表中移除(malloc/malloc.c:4199~4202),同时置位标志位。
而当free时,free会首先尝试将其与前后的空块合并(malloc/malloc.c:4712~4730),之后将其丢近unsorted bin里面。那么问题来了,初始化时既然没有为任何bin赋初值,small bin里的块是哪里来的呢?
来看malloc/malloc.c:4232。这里描述了如何选择合适的bin和chunk:
/*
Process recently freed or remaindered chunks, taking one only if
it is exact fit, or, if this a small request, the chunk is remainder from
the most recent non-exact fit. Place other traversed chunks in
bins. Note that this step is the only place in any routine where
chunks are placed in bins.
The outer loop here is needed because we might not realize until
near the end of malloc that we should have consolidated, so must
do so and retry. This happens at most once, and only when we would
otherwise need to expand memory to service a "small" request.
*/然后,在4310行:
/* place chunk in bin */
if (in_smallbin_range(size)) {
victim_index = smallbin_index(size);
bck = bin_at(av, victim_index);
fwd = bck->fd;
}
else {
//...
}这里就很清楚了。每次malloc的时候,先从unsorted bin中寻找合适的块,如果找到的话,就立刻返回,否则视情况将这个块放入合适的bin12中。这个操作是造成fast bin和其他bin分配速度差异的关键因素。此外,ptmalloc还用位图对不同的bin进行辅助管理,这一点我们可能会在后续的文章中再提13。
Large bin
Large bin和small bin很相似,也是一个binlist,它与small bin的不同点主要是:
- 每个chunk的大小>=512 bytes
- bin中项目不再有固定的大小间隔。在63个items中,32个bin的大小间隔为64 bytes(比如:65# bin里的内存块大小均为512~568 bytes,66# bin里则是576~632 bytes,以此类推),16个bin的间隔为512 bytes,之后依次为4096 bytes、32768 bytes和262144 bytes,最后一个bin则包括了剩下的所有chunks。
- bin中,每个项目虽然也是双链表,但链表中各项的大小不是一样的。他们按照降序排列,大块在前,小块在后。因此,从large bin中获取内存的时候,可能需要进行一次遍历,这也拖慢了分配速度。
那么在试图分配一个大于512字节的large chunk时会发生什么呢?首先,fast bin中所有的item都会被合并(malloc/malloc.c:4229),这是为了让尽可能多的找到合适的项目。之后,malloc会检查large bin是否非空。如果large bin非空的话,就要看情况了:
- malloc会首先利用请求的大小估算一个合适的large bin,并检查该large bin中最大的块是否能够满足需求(
malloc/malloc.c:4376)。如果能的话,就对该item从后到前遍历,直到找到一个合适的chunk,既能满足需求,又不会造成严重的浪费。找到后,这个块会被分为两部分,一部分返回给用户,而另一部分(就是remainder chunk)则会送入Unsorted bin中; - 如binlist中最大的chunk也不能满足需要,那么就会利用一个位图,对所有的bin进行搜索(
malloc/malloc.c:4432),找到合适的chunk后,按照上面的方法分为两部分(malloc/malloc.c:4498)。 - 如果搜索后也没有任何chunk能满足需求,则会使用top chunk(还记得上面我们说过的吗)来分配内存(
malloc/malloc.c:4530)。 - 如果连top chunk也不够分,那么就扩展top chunk(
malloc/malloc.c:4580)。 - 如果top chunk扩展之后也不行的话,恭喜你,malloc会返回0,你是万物之王了(误。
在free一个large chunk的时候,与free(small chunk)基本一致,就不再赘述了。
Unsorted bin
刚才我们多次提到unsorted bin,但把它放到最后来讲,是因为unsorted bin实际很好理解。它是作为一个“缓存”存在的,只占有一个bin,而且里面也只是一个简单的双链表,没有chunk大小限制,也没有其他复杂的结构。其存在意义在于,所有free出的块,如果不属于fast bin,就必须先在unsorted bin中,至少经历一轮malloc,才会视情况分到small bin或者large bin中。
各个bin之间的结构,依然用来自sploitfun的一张图说明:

小结
至此,我用了约20kb的文字,简要的描述了:
- 线程如何从OS获取内存
- 调用malloc及free时,如何分配内存
- 内存分配中涉及到的几种主要数据结构
对堆内存管理机制的介绍就是这些了,比较简单,也可能有很多错误(请不要大意的在评论里写出来),希望能帮助到大家。此外,如果你希望了解更多细节,建议阅读libc源码中malloc文件夹下的malloc.c、arena.c以及tst-malloc.c等相关文件,并阅读与brk和mmap系统调用有关的网页。
最后,仍然用几张图收尾。首先是sploitfun的两张图,这两张图分别展示了,不同情况下,进程内部的内存映射图。


接着是我自己做的两张malloc和free的流程图,建议打开大图查看。(还有点小问题,过段时间一起修)


参考资料
本段主要取材于sploitfun所作的Understanding glibc malloc
临界区是指一个访问共用资源的程序片段。临界区内的资源保证被调用者独享,其他访问者则只能阻塞。
刚才我们说每个线程有自己“独立”的堆结构,严格意义上是不对的。为了确保资源不被浪费,每个进程的arena数量是有限制的。
这里只是简单提一下,一会会详细说明。
arena(/əˈrinə/)有多种译文。这里为了方便,不给出翻译,请自行理解。
注意,主线程不遵循这一规律。当主线程的堆耗尽时,管理器会继续用brk分配内存,直到无法继续分配为止。
注意,主线程的malloc_state存放于libc.so的内存区域中,因为其是一个全局变量。此外,主线程也没有heap_info,因为主线程只有一个堆,不需要多个堆块。
也可以说,malloc返回的地址不是分配得到内存的真正起始地址。
如果你懒得听我说的话,大可以去看malloc/malloc.c:2026开始的代码注释。我只是简单地整理了一下。
最大大小仍然是80字节,但默认只开启到64字节。见malloc/malloc.c:1311
如果是空的,那么其会指向自身。
这里指的是small bin或large bin。fastbin有自己的分配机制,与unsored bin无关。
意思就是我要挖坑了。